Google Memory Caching 论文理解笔记
By Chaa 谷歌这篇二月份的论文,刚好和线性注意力有关,xhs刷到了就翻开来看看哈哈~
论文:Memory Caching: RNNs with Growing Memory
链接:https://arxiv.org/html/2602.24281v1
核心问题:
Transformer 的强召回能力来自“随上下文长度增长的记忆”,但代价是高计算复杂度和高 KV cache 开销。
RNN / Linear Attention / SSM 这类 recurrent 模型虽然便宜,但通常只有固定大小的 hidden state / memory state,长上下文下容易遗忘。
Memory Caching 的目标,就是让 recurrent 模型也拥有一种“可增长的记忆”。
想说的:Ai infra这块的工程或者论文其实现在也算是小小小小有了解了一些,能发现,其实很多的设计就是在架构性能与系统效率上做一个trade-off,这篇也是如此!
0.先备知识
你需要了解如下内容:
机器学习深度学习基础,transformer基础 了解线性注意力是什么(可以看我的transformer架构里的一篇笔记) 简单的线性代数基础,如果还记得多元微积分的话就更好
1. 这篇论文到底在做什么?
它不是在提出传统意义上的 LSTM / GRU。
论文里的 RNN 是广义的 recurrent memory model:
其中:
- :当前时刻的 memory state
- :当前 token 的 key
- :当前 token 的 value
- :当前 token 的 query
- :memory 的更新规则
- :用当前 query 从 memory 中读取信息
这类模型的共同点是:
它们不是保存所有历史 token,而是把历史信息压缩进一个固定大小的 memory state。
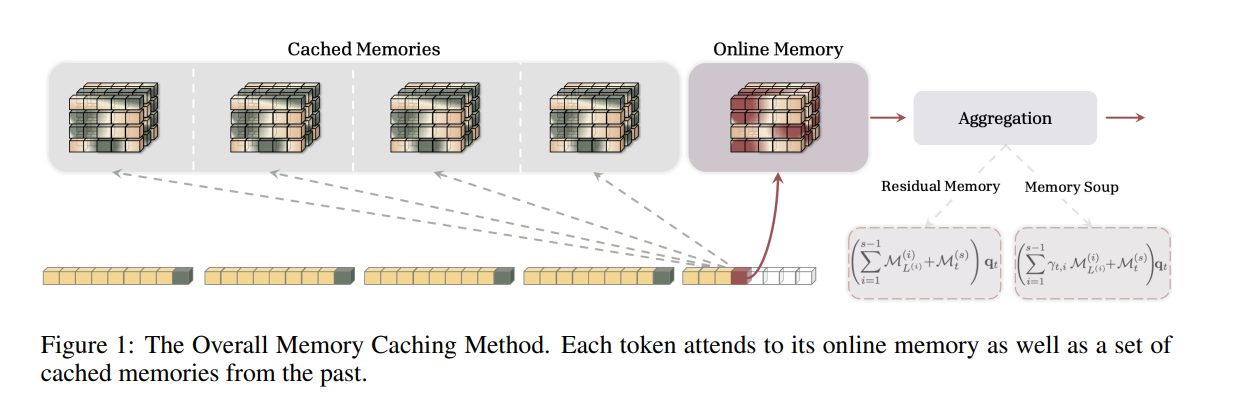
Memory Caching 的改动是:
不要只保留最后一个 memory state。
把序列切成多个 segment,每个 segment 结束时缓存一个 memory checkpoint。
当前 token 读取时,同时访问当前 online memory 和过去 cached memories。
2. Transformer 的记忆:token-level growing memory
标准 causal attention:
Transformer 的关键不是 softmax 本身,而是它保留了所有历史 token 的 key/value:
所以第 个 token 可以直接访问所有过去 token。
这叫:
token-level growing memory
优点是召回能力强。
缺点是计算复杂度高,KV cache 内存开销大,长上下文推理昂贵。
3. Linear Attention 的记忆:固定大小的矩阵 M
Linear Attention 用可分解 kernel 替代 softmax attention,可以写成 recurrent form:
这里 是一个矩阵。
每来一个 token,就把一个外积写进 memory:
如果展开:
读取时:
这和 attention 很像:
query 和历史 key 做相似度;
相似度乘 value;
最后求和。
但区别是:
| 架构 | 历史信息如何保存 |
|---|---|
| Transformer | 显式保存每个历史 token 的 K/V |
| Linear Attention | 把历史 token 压缩进一个固定矩阵 |
问题在于:
这个矩阵大小不随上下文增长。
无论上下文有 1K token 还是 1M token,最后都要被压进同一个 。
所以 Linear Attention 的瓶颈是:
计算便宜,但 memory capacity 固定。
4. Memory Caching 的核心公式
论文把输入序列切成多个 segment:
每个 token 生成:
第 个 segment 内部,memory 正常更新:
segment 结束时,缓存这个 segment 的最终 memory:
普通 recurrent model 只读当前 memory:
Memory Caching 改成:
这条公式是整篇论文的主干。
含义是:
当前 token 不只读取当前 online memory,还读取过去每个 segment 的 cached memory。
所以它从:
一个固定 memory
变成:
多个分段 memory checkpoints
这就是它所谓的 RNNs with Growing Memory。
5. Agg 函数到底做什么?
Agg 不是一个固定函数,而是一个抽象接口。
它要解决的问题是:
给定当前 query ,如何从当前 online memory 和过去 cached memories 里读取信息,并合成最终输出 ?
具体来说,Agg 要决定:
- 读哪些 memory?
- 每个 memory 怎么读?
- 每个 memory 的结果占多大权重?
- 最后怎么合成输出?
论文给了几个具体版本:
- Residual Memory
- Gated Residual Memory
- Memory Soup
- Sparse Selective Caching
6. Residual Memory:全部读取,直接相加
最简单的 Agg 是:
含义是:
当前 online memory 读一次;
过去每个 cached memory 都读一次;
然后全部相加。
如果当前在第 5 段:
优点是简单。
缺点是所有历史 memory 被同等对待。
也就是说,不管当前 token 和哪一段相关,所有 cached memories 都会被加进来。
7. 线性 memory 下为什么可以合并?
如果 memory 是线性矩阵:
那么 Residual Memory 变成:
因为矩阵乘法满足分配律,所以可以写成:
也就是说,可以先把所有 memory 加成一个总矩阵:
然后:
所以,在 纯线性 memory + 无门控 + 直接相加 的版本里,Memory Caching 确实会退化。
这也是为什么论文真正有意义的地方不是这个朴素 residual 版本,而是:
- query-dependent gating
- sparse selective routing
- deep / non-linear memory
8. Gated Residual Memory:按相关性加权读取
为了避免所有 cached memories 同等对待,论文引入 gate:
其中:
表示当前 token 对第 段 memory 的依赖程度。
如果:
表示第 段很重要。
如果:
表示第 段可以忽略。
论文给的一个计算方式是:
实践中通常会再做 softmax 归一化。
含义:
当前 token 生成一个 connector 向量 ;
每个历史 segment 有一个 mean-pooled 表示;
二者越相似,说明当前 token 越应该读取那段 memory。
所以 Gated Residual Memory 本质上是:
segment-level attention over cached memories
注意,它不是对历史 token 做 attention,而是对历史 segment 的 memory checkpoint 做 attention。
9. 为什么带 γ 后不能提前合并?
如果 memory 是线性矩阵,GRM 可以写成:
对某一个固定 token 来说,确实可以临时合并:
但不能提前合并成一个长期复用的固定矩阵,因为:
每个 token 的 gate 都不同。
所以最多只能:
针对当前 token 临时合并
不能:
预先合并成一个固定 memory,后续所有 token 复用
这就是论文说带 input-dependent gate 后不会退化成普通 fixed-size memory 的原因。
10. Sparse Selective Caching:先选 Top-k,再读取
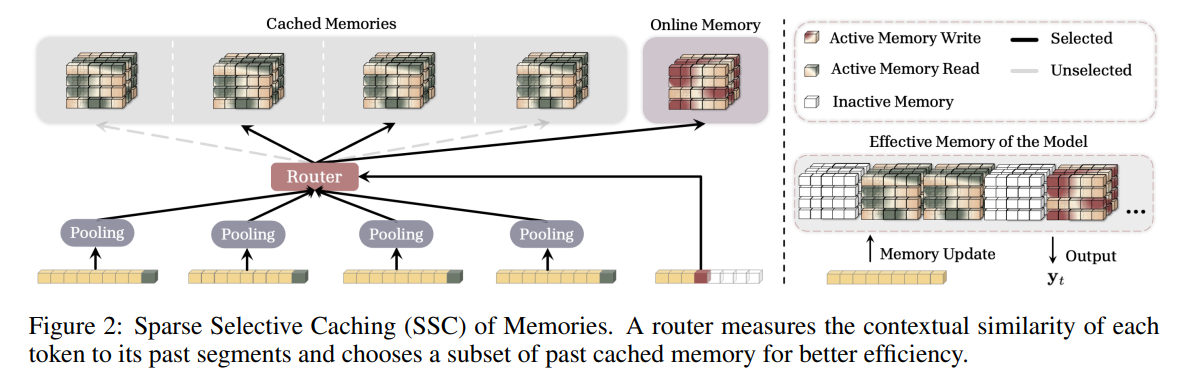
Gated Residual Memory 还有一个问题:
如果历史 segment 很多,每个 token 都读所有 cached memories,还是贵。
所以论文提出 Sparse Selective Caching,简称 SSC。
它先计算当前 token 和每个历史 segment 的相关性:
然后选 Top-k:
最后只读取被选中的 memories:
含义:
过去每个 cached memory 像一个 expert;
当前 token 只激活最相关的几个 expert。
这和 MoE 很像:
| Memory Caching | MoE |
|---|---|
| cached memory | expert |
| router | router |
| Top-k memories | activated experts |
SSC 的价值在于:
cache 的问题不是“存不存”,而是“怎么选中该读的 cache”。
这点和 prefix cache / radix tree / KV cache selection 的系统直觉很接近。
11. Memory Soup:不是混输出,而是混 memory 参数
前面几种方法都是:
每个 memory 先对 做 forward,得到多个输出,再加权合成输出。
Memory Soup 不一样。
它先把多个 memory 的参数混成一个新的 memory:
然后:
也就是说:
GRM 是先分别读取,再混输出。
Memory Soup 是先混 memory 参数,再用混出来的新 memory 读取。
如果 memory 是线性矩阵:
所以 Memory Soup 和 GRM 等价。
但如果 memory 是 MLP:
则一般有:
所以 Memory Soup 的意义主要在 deep memory,比如 DLA / Titans。
它相当于:
当前 token 根据上下文,临时拼出一个专属 memory network。
12. M 到底是什么?为什么说它内部像 MLP?
这是最容易误解的地方。
从实现上看, 当然是张量,或者一组张量。
但论文关心的是这些张量扮演什么角色。
情况一:线性 memory
如果 是矩阵:
读取就是:
这时 就是一个普通矩阵张量。
情况二:deep memory
如果 是一个两层 MLP,那么它不是单个矩阵,而是一组参数:
读取时:
所以:
的底层是张量集合;
但它被当成一个函数 来调用;
当这个函数是 MLP 时,就可以说 memory 内部像一个 MLP。
更准确地说:
不是普通 activation tensor,而是一组 fast weights。
这些 fast weights 在 forward 过程中随着 token 动态变化。
13. 到底怎么更新?
13.1 线性版本
Linear Attention 的 memory update 是:
每来一个 token,就往 memory 矩阵里加一个外积。
这不是 MLP,只是矩阵累加。
13.2 DLA 版本
DLA 的 memory update 是:
读取是:
DLA 的 objective 可以写成:
含义:
当前 token 产生 和 。
memory 用 做一次 forward,得到 。
根据 和 的匹配程度,计算一个内部损失。
对 memory 参数求梯度。
用这个梯度更新 memory,得到新的 。
如果 是两层 MLP:
更新后:
其中:
所以 deep memory 的更新更像:
用当前 token 构造一个小训练样本 ,
在 forward 内部对 memory MLP 的参数做一步内循环更新。
13.3 Titans 版本
Titans 的 update 更像带动量的内循环优化器:
读取:
Titans 的 objective 是:
这很直观:
让 memory network 学会把 key 映射到 value。
也就是:
其中:
- :内部学习率
- :memory retention
- :momentum / update smoothing
- :optimizer-like update state
所以 Titans 可以理解成:
在 forward 过程中,用一个小优化器动态更新 memory network 的参数。
14. 每个 segment 的 M_0 是继承上一段,还是重新初始化?
论文里两种都允许。
这个问题对应论文里的:
Caching Checkpoints or Independent Compressors?
方案 A:继承上一段,缓存同一个 memory 的 checkpoint
公式:
流程:
- 第 1 段从 开始更新,结束后缓存
- 第 2 段从 继续更新,结束后缓存
- 第 3 段从 继续更新
这叫 checkpoint view。
直觉:
一个 memory 连续学习整个上下文,每段结束时拍一张快照。
优点:
上下文连续性强。
缺点:
后面的 token 仍然可能污染或覆盖前面的 memory,只是历史快照被保留下来了。
方案 B:每段独立 compressor
每个 segment 的 memory 从独立初始点开始:
流程:
- segment 1 用自己的 memory 压缩自己
- segment 2 用自己的 memory 压缩自己
- segment 3 用自己的 memory 压缩自己
这叫 compression perspective。
直觉:
每个 segment 有自己的压缩器,每个 cached memory 只代表自己那一段。
优点:
段间不互相污染,更适合 retrieval / needle / 段级 recall。
缺点:
跨段连续状态弱。
15. 复杂度:为什么它是 RNN 和 Transformer 的中间态?
假设序列长度为 ,segment 数为 。
每个 token 读取 个 cached memories,整体复杂度大约是:
两个极端:
情况一:
整个序列只有一个 segment。
这就退回普通 RNN / Linear Attention。
情况二:
每个 token 都是一个 segment。
这就接近 Transformer。
所以 Memory Caching 给了一个连续谱:
如果每段长度固定为 :
那么复杂度类似:
越大:
压缩越强,计算越便宜,但召回越弱。
越小:
记忆越细,越接近 attention,但越贵。
16. 个人认为这篇文章,作为一个学习者应该关注的
注意好它和线性attention的区别
并不是线性 memory 相加。
因为纯线性 residual 版本确实容易退化,所以文章也据此提出了多种分化路径来解决。
一个比较准确的理解是:
它提出了一种分段 fast-weight memory + query-dependent retrieval 的框架,用来给 recurrent 模型补上类似 Transformer 的 growing memory capacity。
对于文章贡献,认为比较有价值的部分是:
1. 分段 memory checkpoints
不是只保留最后一个 ,而是保留多个历史段的 。
2. Query-dependent retrieval
当前 token 根据自己的上下文决定读哪些 memory、怎么加权读。
3. Sparse selective routing
不是所有 cached memories 都读,而是 Top-k 选择。
4. Deep / non-linear memory
可以不是一个矩阵,而是一个动态更新的 MLP 参数集合。
线性 memory 下:
容易合并,表达力有限。
deep memory 下:
不同 memory 的参数、输出、聚合方式不再简单等价。
另外就是注意好一个元思维:就像开头说的,文章是怎么在性能与效率上进行权衡的呢?
17. 和 Transformer / KV cache 的关系
(一开始我看到这个caching,下意识以为又是在推理环节做的优化)
Transformer KV cache 保存的是:
这是 token-level memory。
Memory Caching 保存的是:
这是 segment-level memory。
区别:
| 机制 | 缓存对象 | 记忆粒度 | 优点 | 缺点 |
|---|---|---|---|---|
| RNN | 一个 hidden / memory state | 极粗 | 便宜 | 容易忘 |
| Transformer KV cache | 每个 token 的 K/V | 极细 | 召回强 | 贵 |
| Memory Caching | 每个 segment 的 memory checkpoint | 中等 | 折中 | 不如 full attention 精确 |
一句话:
Memory Caching 不是压缩 Transformer 的 KV cache,而是试图让 recurrent 模型拥有自己的 growing memory。
18. 最终理解
这篇论文的主线可以压缩成一句话:
Transformer 强在它有 token-level growing memory;
RNN / Linear Attention 弱在它只有 fixed-size compressed memory;
Memory Caching 通过缓存多个 segment-level memory checkpoints,让 recurrent 模型获得一种可控成本下的 growing memory。
更直接地说:
其中真正重要的分界线是:
还是:
前者是线性矩阵记忆,容易合并退化。
后者是动态 fast-weight memory,能提供更复杂的查询和组合能力。
所以这篇论文最值得关注的不是最简单的 Residual Memory,而是:
GRM / SSC + DLA / Titans 这类 deep memory 的组合。
它本质上是在探索:
如何用更便宜、更可控的方式,给非 Transformer 架构补上长上下文召回能力。